HTTP Request Smuggling pour les nuls
Introduction
Aujourd’hui, nous allons voir une vulnérabilité peu connu, le HTTP request smuggling ou contrebande de HTTP en français (trop stylé ouai).
Derrière ce terme un peu barbare qu’est le HTTP Request Smuggling se cache une vulnérabilité très intéressante.
DISCLAIMER : Pour ce blog post, je pars du principe que vous êtes familier techniquement avec le protocole HTTP, si ce n’est pas le cas, j’ai sorti une vidéo ainsi qu'un blog post sur le sujet.
Avant de parler du request smuggling, petit retour en arrière sur HTTP et ses versions pour bien comprendre l’origine de la vulnérabilité.
Ancienne version de HTTP
Version 0.9
Il faut savoir qu’avant, lors sa version 0.9, le seul moyen d'envoyer 3 requêtes était d'ouvrir 3 fois une connexion TCP/IP avec le serveur et à chaque fois demander le document ciblé, c’était plutôt contraignant et gourmand en ressource comme vous pouvez l’imaginer
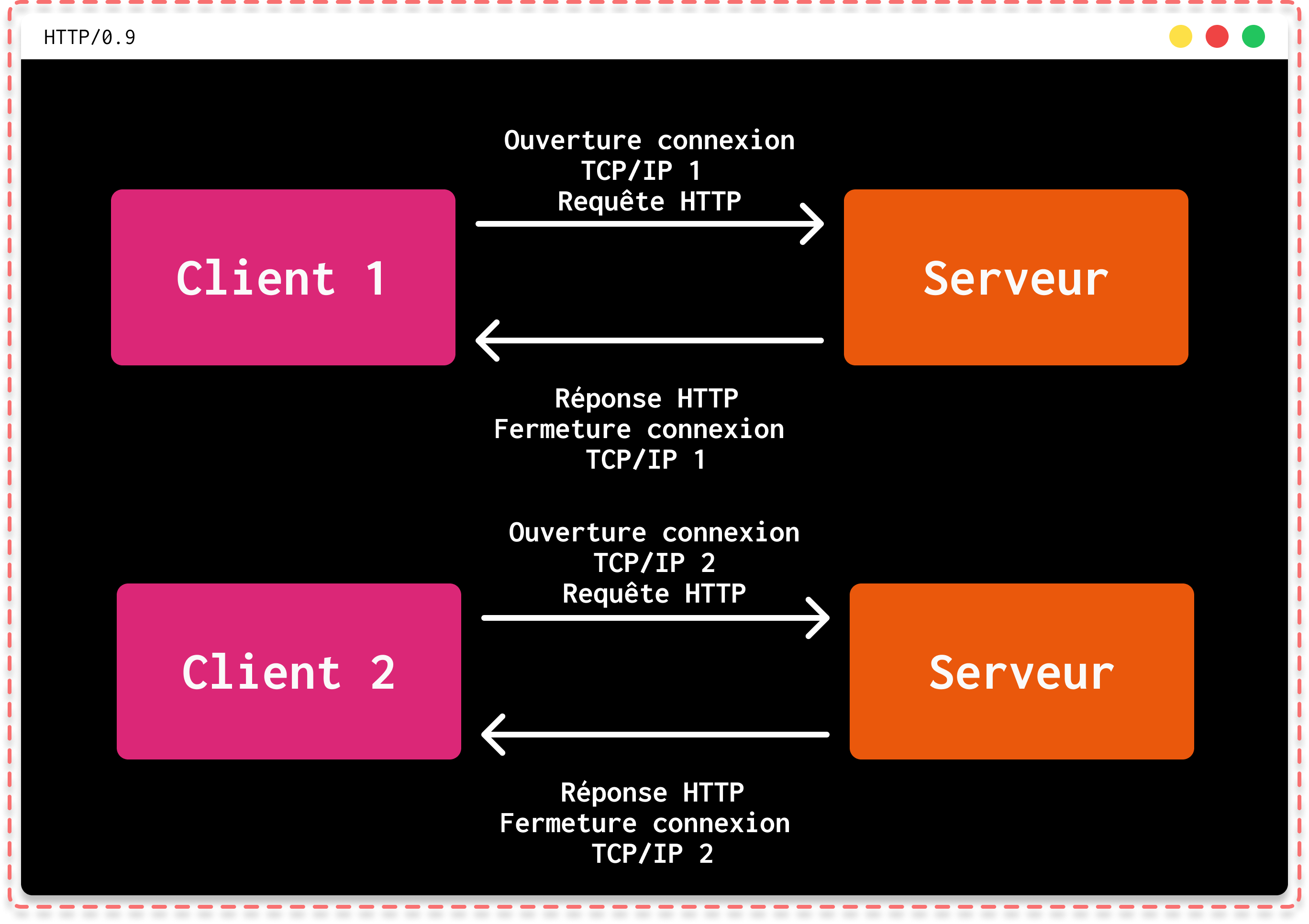 |
|---|
| Fonctionnement de HTTP en version 0.9 |
HTTP était et reste à ce jour un protocole assez simple, surtout dans sa version 0.9. Retenez l'utilisation de \r\n pour représenter les caractères CR et LF, les marqueurs de fin de ligne. Cela aura son importance plus tard.
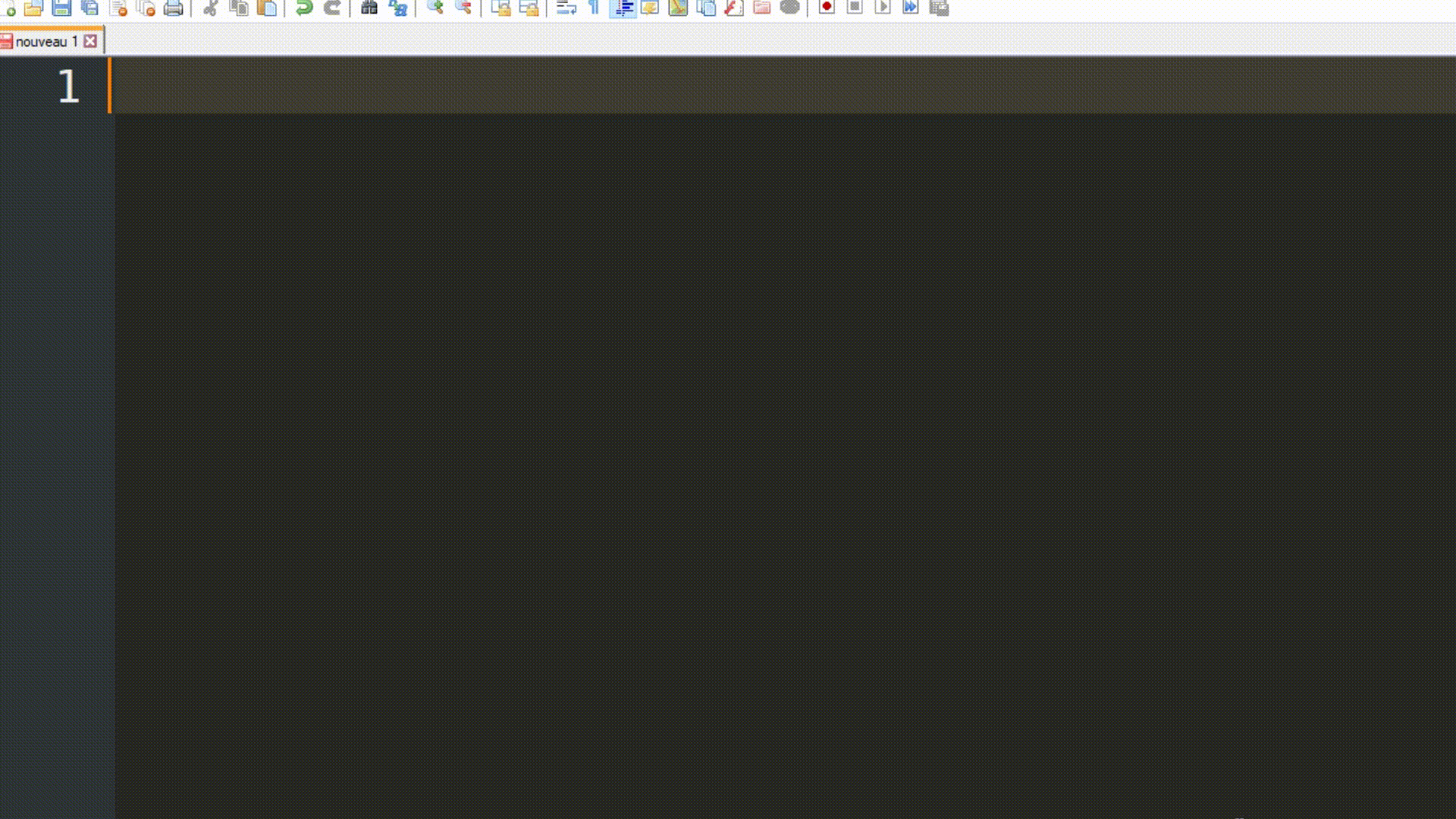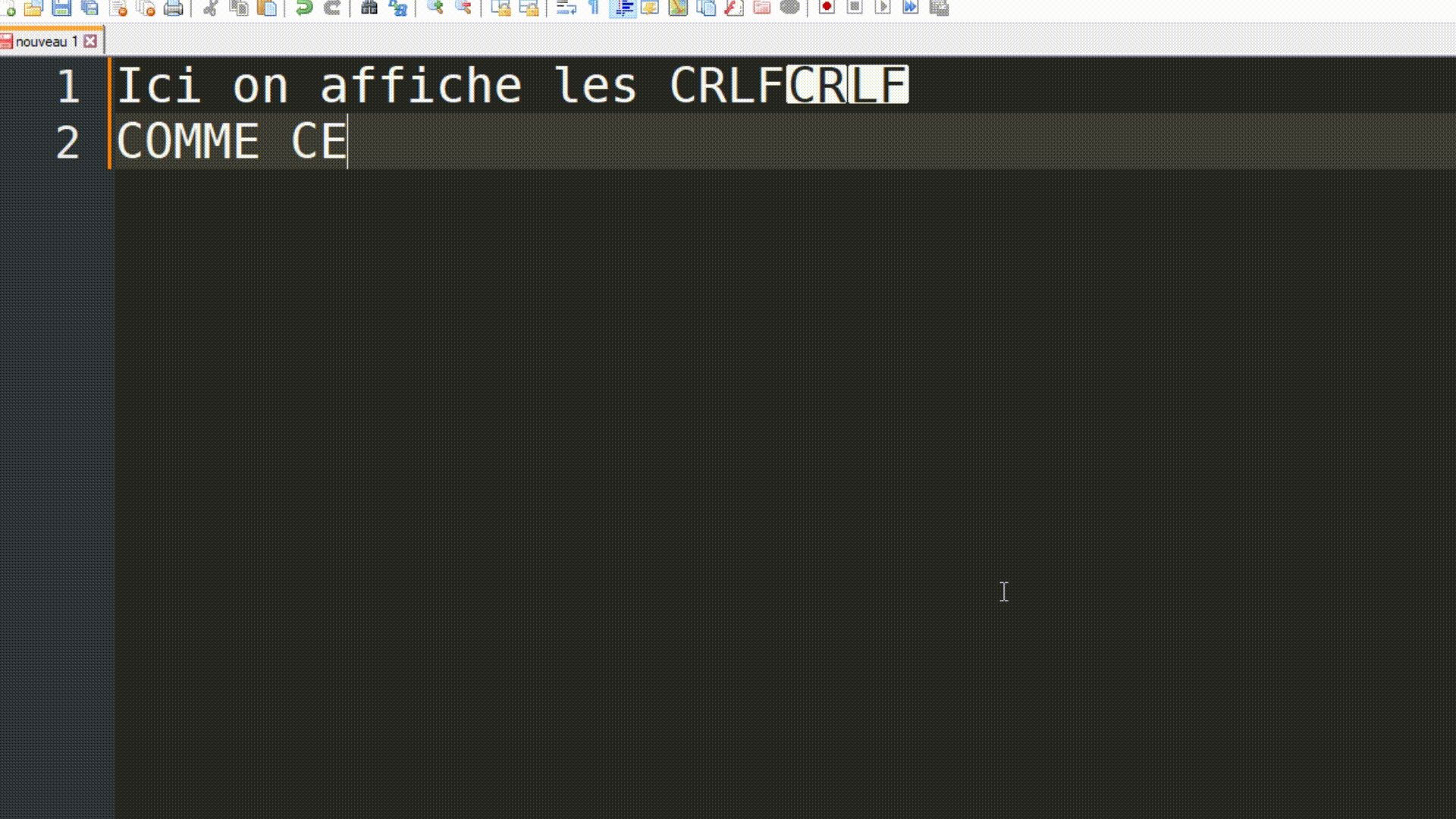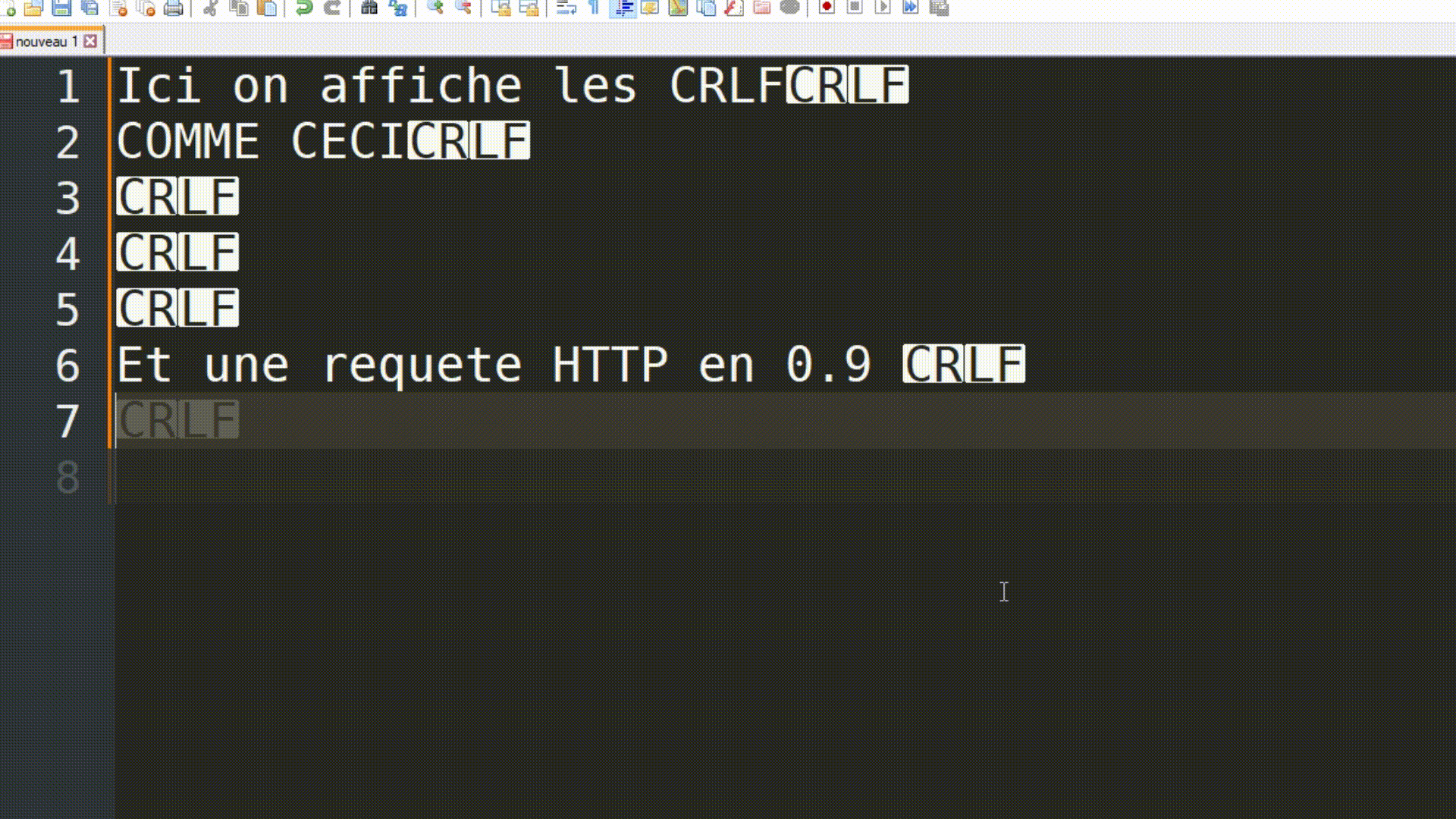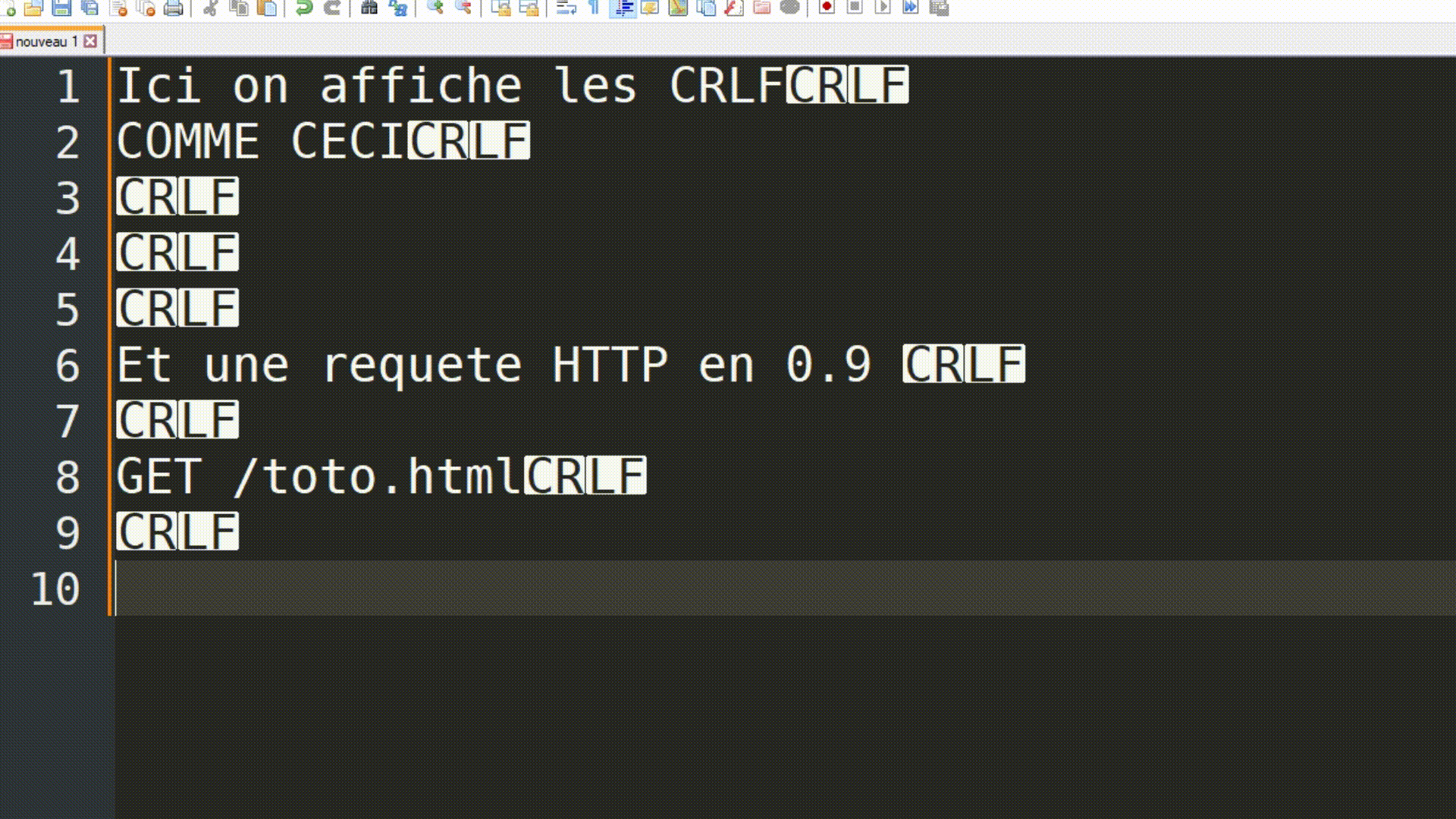 |
|---|
| Explication de ce qu'est \r\n (permettant de marquer la fin de ligne) |
Version 1.0
Arrive la version HTTP\1.0 qui apporte une chose très importante vu dans la vidéo & blog post HTTP, les en-têtes ou headers. Voici la requête ci-dessus mais en HTTP\1.0 :
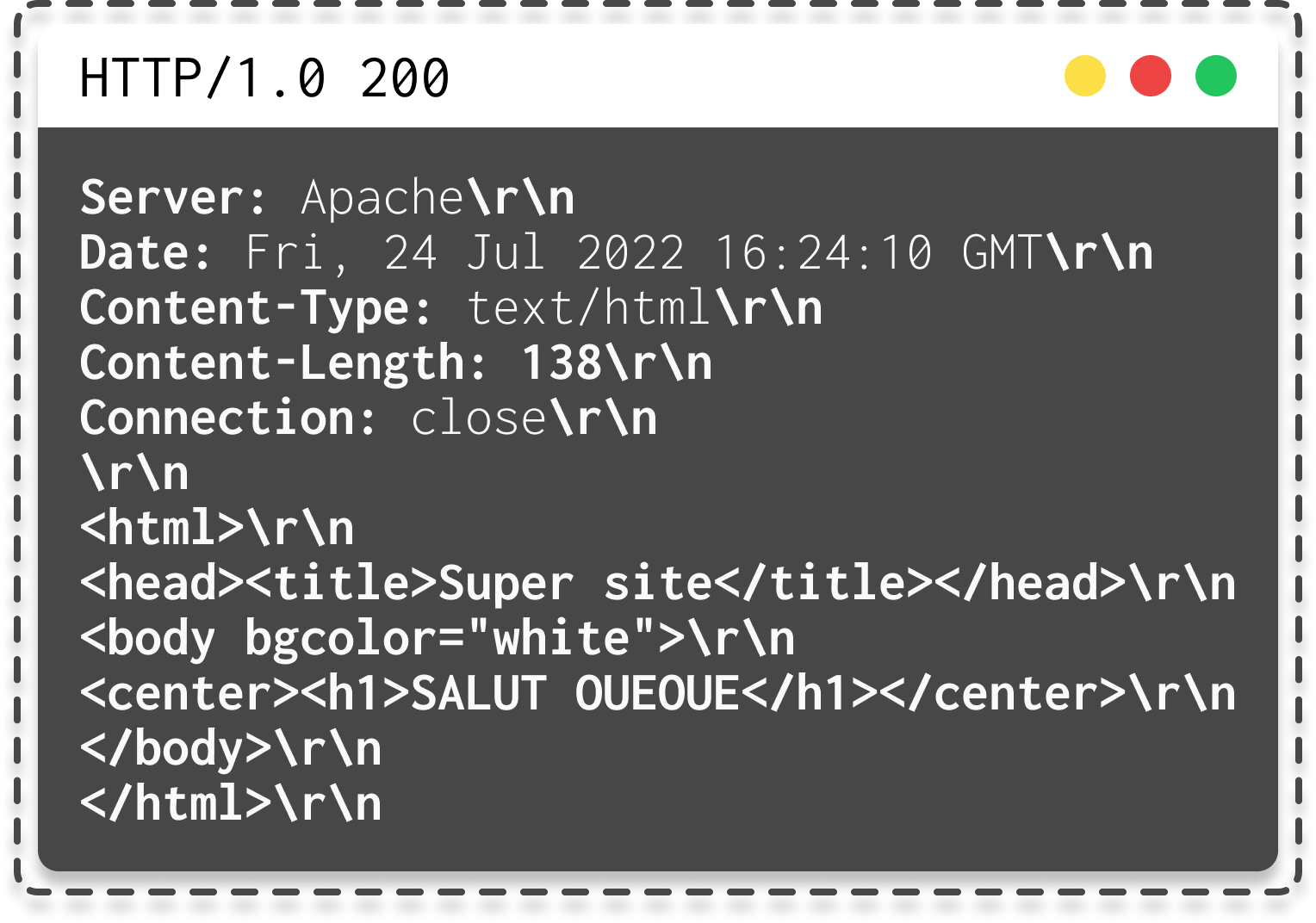 |
|---|
| Fonctionnement de HTTP en version 1.0 avec \r\n affiché |
Il est important de remarquer le header Content-Length, ce dernier correspond au nombre de caractère ascii7 en démarrant à <html en incluant les caractères de fin de ligne soit 138 octets.
Retenez que, pour bien comprendre le request smuggling, la taille c'est super important (on reste dans le contexte de HTTP bien sûr).
Version 1.1
Arrive la version HTTP/1.1 qui ajoute trois choses importantes (surtout pour comprendre le request smuggling) :
- le mode Keep-Alive
- les requêtes Pipelined
- les requêtes et réponses Chunked
Keep-Alive
Le mode Connection : Keep Alive est un header qui indique au serveur qu’il peut réaliser plusieurs requêtes/réponses dans la même connexion TCP/IP.
Comme vous vous en doutez, cela change beaucoup par rapport à la version 0.9 où chaque requête nécessitait l'ouverture d'une connexion TCP/IP.
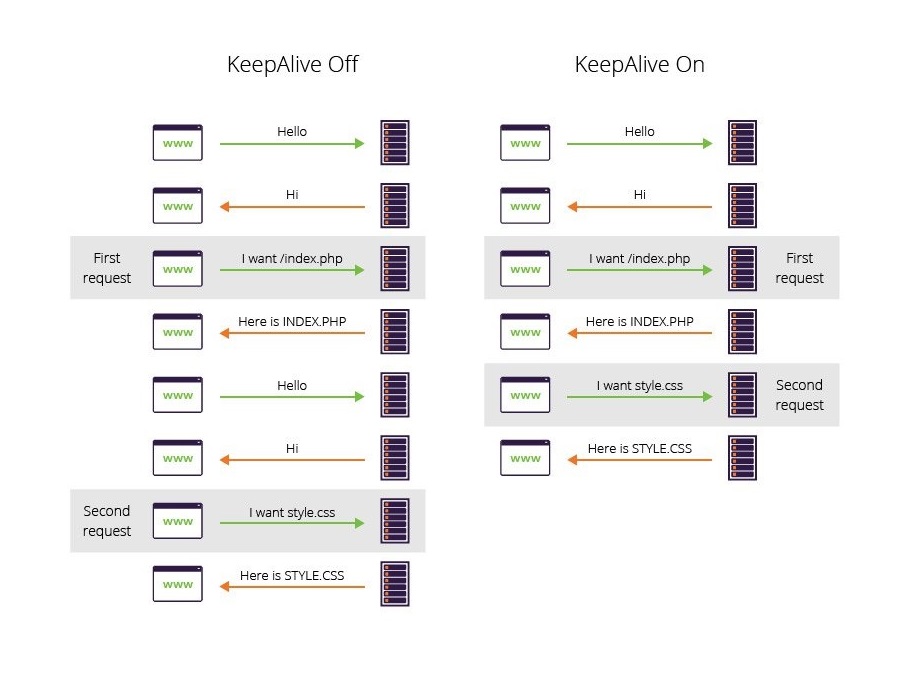 |
|---|
| Fonctionnement du header keep-alive (source: imperva) |
Il est aussi possible de spécifier Connection: Close qui signifiera au serveur de couper la connexion après le premier échange requête/réponse. Néanmoins, retenez que le mode Keep alive est très utilisé car souvent activé par défaut sur les serveurs web afin d’optimiser les connexions.
Pipelining
L’autre grosse nouveauté de cette version HTTP est le pipelining. Ce concept consiste à combiner plusieurs requêtes HTTP dans une seule connexion TCP sans attendre les réponses correspondant à chaque requête. Comme vous l'aurez surement compris, le fonctionnement du pipelining repose grandement sur le header Keep alive vu juste au-dessus.
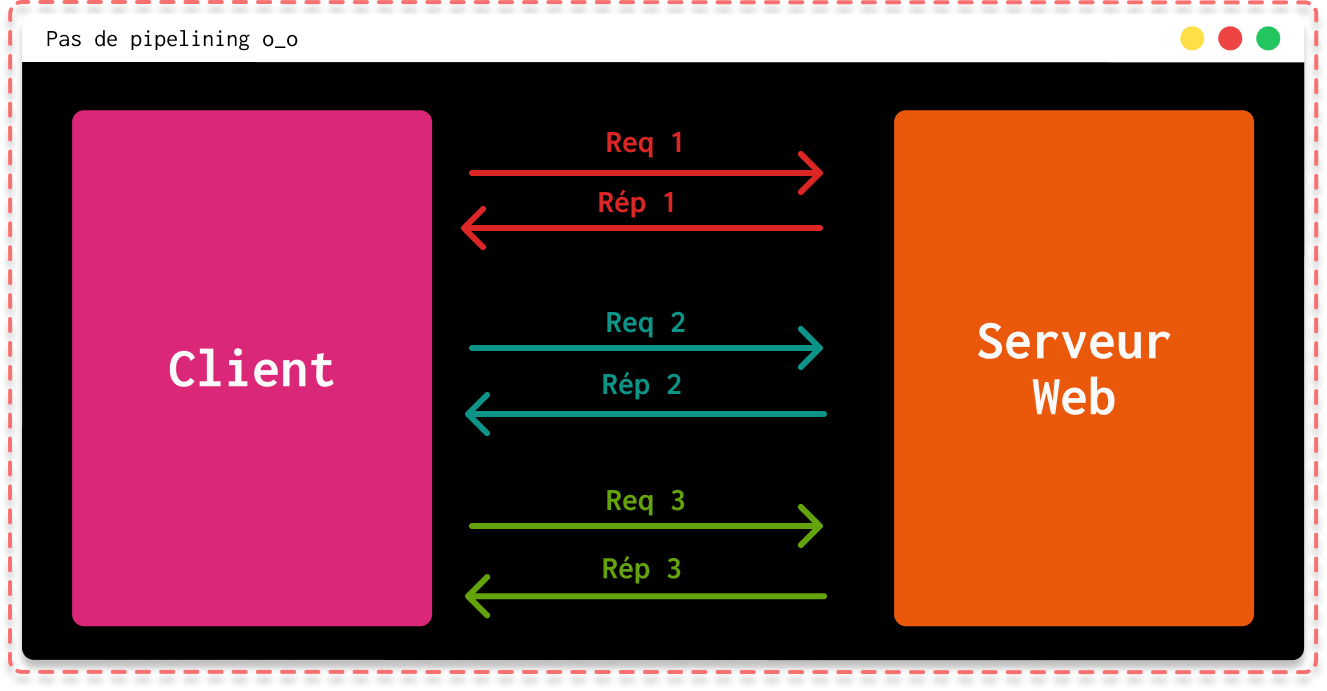 |
|---|
| Fonctionnement sans pipelining |
Cela permet d'optimiser grandement la vitesse requête/réponse car la personne B n'aura pas à attendre la réponse de la personne A pour récupérer sa réponse !
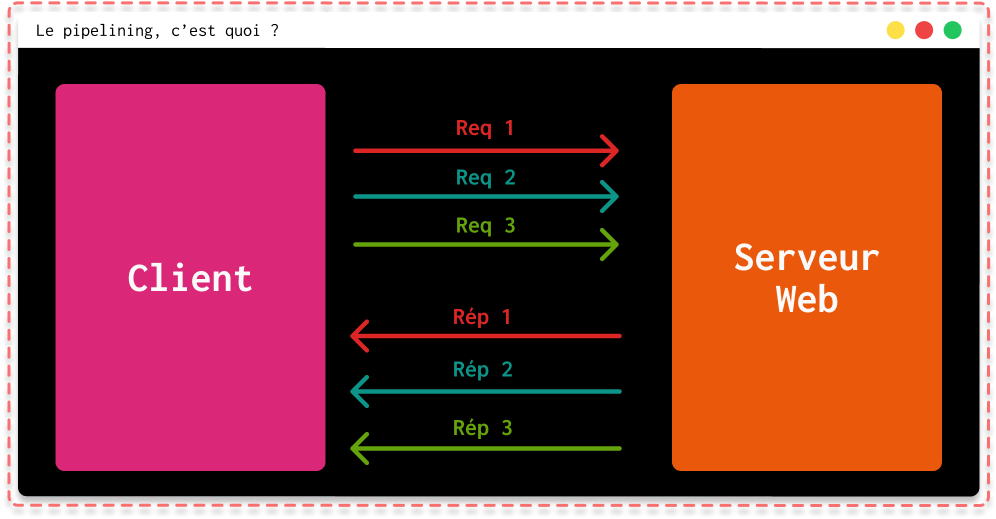 |
|---|
| Fonctionnement avec pipelining |
Chunks
Enfin, la version 1/1 apporte le transfert chunked (Transfer-Encoding: chunked), c’est un moyen alternatif au header Content-length.
Tandis que Content-length annonce la taille complète finale du message (comme vu précédemment).
Le transfert Chunk, quant à lui, permet de transmettre un message par plusieurs petits paquets (chunks), chacun annonçant sa taille grâce à un dernier chunk spécial avec une taille vide pour clôturer la fin du message. On remarque à nouveau les \r\n AKA CRLF.
 |
|---|
| Représentation des chunks dans une requête HTTP |
HTTP Request Smuggling
C’était long, mais maintenant, vous avez toutes les clés en main pour comprendre le request smuggling.
Récapitulons :
- Les requêtes/réponses HTTP sont des listes de chaînes de caractères séparées par des marqueurs de fin de ligne (return carriage).
- L’agent HTTP qui lit les requêtes doit savoir où cette liste de chaîne s’arrête afin de séparer les différentes requêtes HTTP. Pour faire cela, l’agent HTTP se base sur le header Transfer-Encoding ou le header Content-Length.
- Les applications web actuelles fonctionnent souvent avec un front end et un backend.
- Avec le Keep Alive et les pipelines, il est possible d’envoyer plusieurs requêtes sur la même connexion TCP/IP et sans attendre le retour.
Dans une architecture avec un frontend et un backend :
Lorsque le serveur frontend transmet des requêtes HTTP à un serveur backend, il envoie généralement plusieurs requêtes via la même connexion TCP/IP comme on l’a vu avec le pipelining.
Il faut donc que le front et le back se mettent d’accord sur les limites entre les requêtes, sinon, un attaquant pourra envoyer une requête ambiguë qui est interprétée différemment par le front et le back.
Le HTTP Request Smuggling se produit lorsqu’un attaquant envoie une requête au front qui contient deux requêtes HTTP en une.
Cela semble un peu flou pour le moment, nous allons voir comment cela est possible !
Comment ça fonctionne ?
La plupart des vulnérabilités liées au request smuggling sont dues au fait que la spécification HTTP prévoit deux façons différentes de spécifier où se termine une requête : l'en-tête Content-Length et l'en-tête Transfer-Encoding.
Étant donné cette spécificité, il est possible qu'un même message utilise les deux méthodes à la fois, de sorte qu'elles entrent en conflit l'une avec l'autre.
Le request smuggling consiste à placer l'en-tête Content-Length et l'en-tête Transfer-Encoding dans une seule requête HTTP et à les manipuler de manière à ce que les frontend et backend traitent la requête différemment.
Prenons cette requête HTTP :
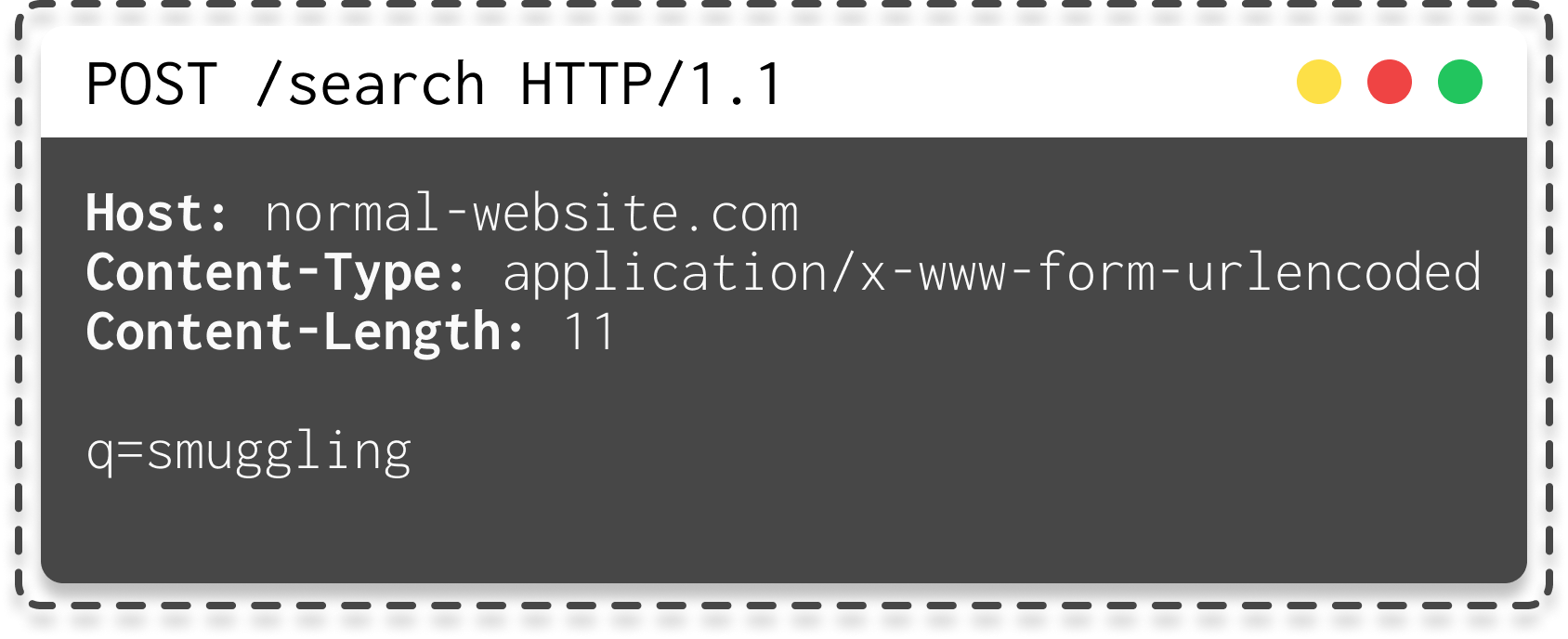 |
|---|
| Requête HTTP en POST |
Comme vous pouvez le voir, même si les deux serveurs utilisent un header différent pour déterminer la taille de la requête, tout se passe bien.
 |
|---|
| Comportement de deux serveurs concernant cette requête HTTP |
Mais que se passe-t-il si un attaquant ajoute un deuxième header indiquant la taille à la fin de la requête ??
Ce dernier va ajouter l'en-tête Transfer-Encoding utilisé pour spécifier que le corps du message utilise un encodage par morceaux.
Cela signifie que le corps du message contient un ou plusieurs morceaux de données. Chaque bloc se compose de la taille du bloc en octets (exprimée en hexadécimal), suivie d'une nouvelle ligne, puis du contenu du bloc. Le message se termine par un bloc de taille zéro.
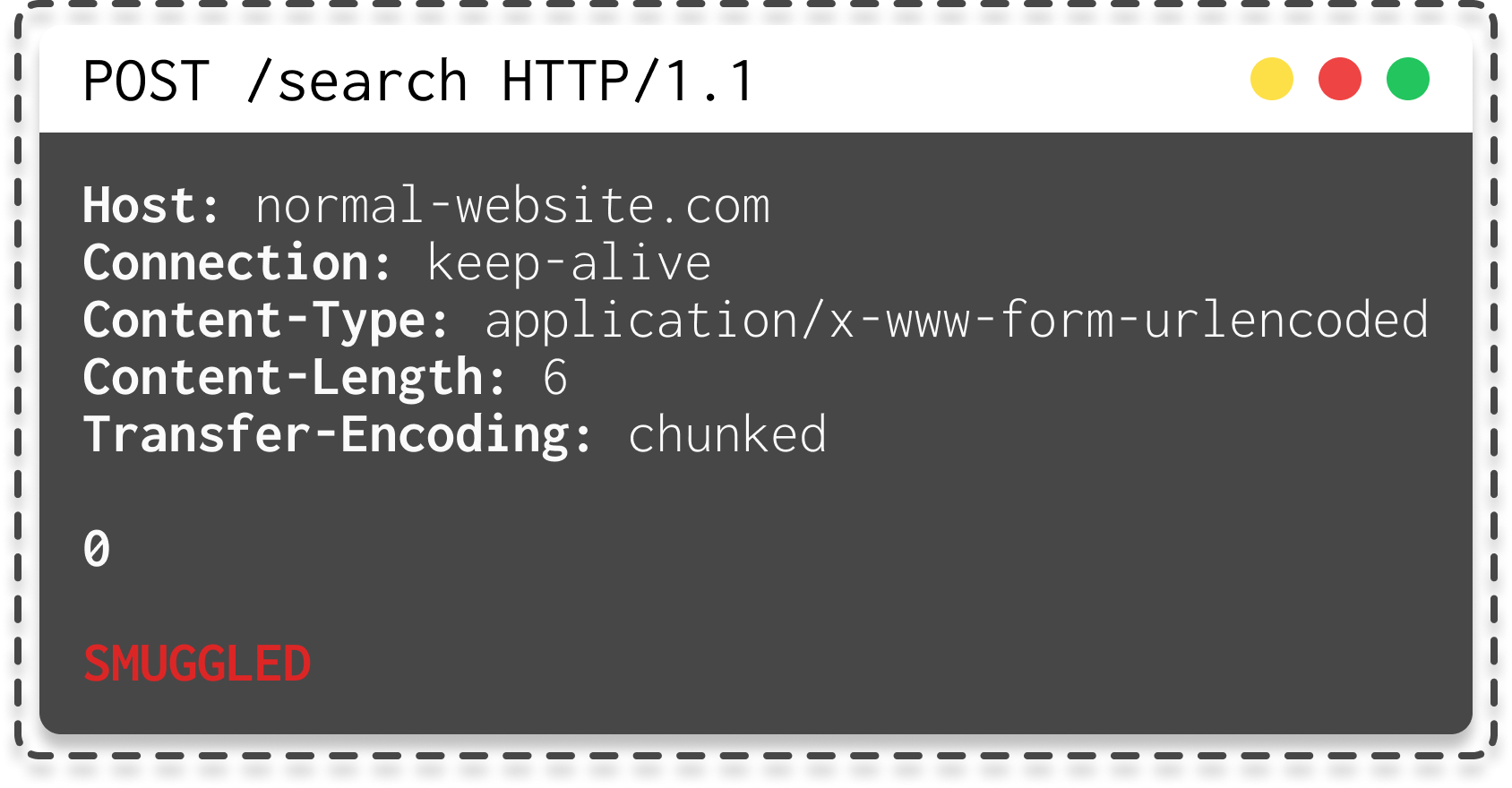 |
|---|
| Requête HTTP pour effectuer un request smuggling |
Alors, il se passe quoi ?
Comme vous pouvez le voir dans le gif, le serveur frontal traite l'en-tête Content-Length et détermine que le corps de la requête est long de 6 octets, jusqu'à la fin de SMUGGLED. Cette demande est transmise au backend.
Le backend traite l'en-tête Transfer-Encoding et considère donc le corps du message comme utilisant ce header.
Il traite le premier morceau, qui est déclaré de longueur nulle, et est donc considéré comme mettant fin à la demande (parce que \r\n0\r\n\r\n). Les octets suivants, SMUGGLED, ne sont pas traités et le serveur backend les considère comme le début de la requête suivante. Donc, SMUGGLED est traité comme une nouvelle requête, il serait possible d’intégrer un payload comme “GET /admin” pour bypass le frontend et accéder au panel d’administration.
 |
|---|
| Fonctionnement du request smuggling |
Il existe plusieurs sortes de request smuggling en fonction du comportement des deux serveurs :
- CL.TE : le serveur frontend utilise l'en-tête Content-Length et le serveur backend utilise l'en-tête Transfer-Encoding.
- TE.CL : le serveur frontend utilise l'en-tête Transfer-Encoding et le serveur backend utilise l'en-tête Content-Length.
- TE.TE : le serveur frontend et le serveur backend supportent tous deux l'en-tête Transfer-Encoding, mais l'un des serveurs peut être incité à ne pas le traiter en obscurcissant l'en-tête d'une manière ou d'une autre.
Maintenant que le request smuggling est plus clair pour vous, passons à la démonstration !
Request Smuggling CL.TE
Cliquez pour voir l'exemple de Request Smuggling CL.TE.

Impacts
- Contournement des contrôles de sécurité : Le request smuggling peut permettre à un attaquant de contourner les contrôles de sécurité mis en place sur un serveur web. Cela peut inclure le contournement des règles de pare-feu d'applications web (WAF) et d'autres mécanismes de sécurité, permettant ainsi à l'attaquant d'accéder à des ressources non autorisées.
- Exposition de données sensibles : En exploitant une vulnérabilité de request smuggling, un attaquant peut accéder à des données sensibles ou confidentielles. Cela peut inclure des informations personnelles des utilisateurs, des données financières ou toute autre donnée qui devrait être protégée.
- Altération de données : Le request smuggling peut permettre à un attaquant de modifier les données transmises entre le client et le serveur. Cela peut conduire à des modifications indésirables de données, à des falsifications de contenu, ou même à des attaques de type "man-in-the-middle" où un attaquant intercepte et modifie les données en transit.
- Altération de la logique d'application : En exploitant une vulnérabilité de request smuggling, un attaquant peut altérer la logique d'application et contourner les contrôles d'autorisation ou les mécanismes de sécurité. Cela peut lui permettre d'accéder à des fonctionnalités ou à des actions normalement restreintes.
Mesures correctives
Pour éviter les vulnérabilités liées au request smuggling, voici les mesures à suivre :
- Utiliser HTTP/2 de bout en bout et désactiver le downgrade HTTP si possible. HTTP/2 utilise un mécanisme robuste pour déterminer la longueur des requêtes et, lorsqu'il est utilisé de bout en bout, il est intrinsèquement protégé contre le request smuggling. Si vous ne pouvez pas éviter le downgrade HTTP, assurez-vous de valider la demande réécrite par rapport à la spécification HTTP/1.1. Par exemple, rejeter les demandes qui contiennent des nouvelles lignes dans les en-têtes, des deux-points dans les noms d'en-têtes et des espaces dans la méthode de requête.
- Faites en sorte que le serveur frontal normalise les demandes ambiguës et que le serveur final rejette celles qui le sont encore, en fermant la connexion TCP au passage.
- Ne jamais supposer que les requêtes n'auront pas de corps. C'est la cause fondamentale des vulnérabilités de CL.0 et de la désynchronisation côté client.
- Abandonnez la connexion par défaut si des exceptions au niveau du serveur sont déclenchées lors du traitement des requêtes.
Ressources
http-smuggling | makina-corpus
HTTP-keep-alive | imperva
HTTP request smuggling| portswigger
http-request-smuggling | thehacker.recipes