HTTP pour les nuls
Introduction
À l'origine, je prévoyais de rédiger un article de blog sur le trafic de requêtes (request smuggling), une vulnérabilité liée à HTTP, mais regrouper l'explication du protocole et l'explication de la vulnérabilité dans un seul article est trop long.
Alors vulgarisons HTTP !
HTTP signifie HyperText Transfer Protocol (protocole de transfert hypertexte). HTTP est un protocole de communication utilisé pour échanger des données sur le Web.
Une affaire de client/serveur
HTTP fonctionne en tant que client/serveur. Voici une analogie rapide pour vous aider à comprendre.
Imaginons que dans un restaurant, le client envoie une demande au serveur du restaurant (le serveur) pour un plat particulier (une ressource web, par exemple une page) en utilisant le menu (la page web sur laquelle vous vous trouvez). Le serveur répond alors avec le plat demandé (la ressource).
 |
|---|
| Affaire de client/serveur |
Tout comme le client peut faire plusieurs demandes pour différents plats, le navigateur peut également faire des demandes pour différentes ressources, telles que des images, des pages web ou des vidéos. Le serveur répondra à chaque demande avec la réponse appropriée, tout comme un serveur de restaurant apporterait le plat demandé à la table.
De plus, tout comme un restaurant peut avoir différentes tables pour différents clients, un serveur web peut traiter de multiples demandes de différents clients en même temps, servant des ressources différentes à chaque client.
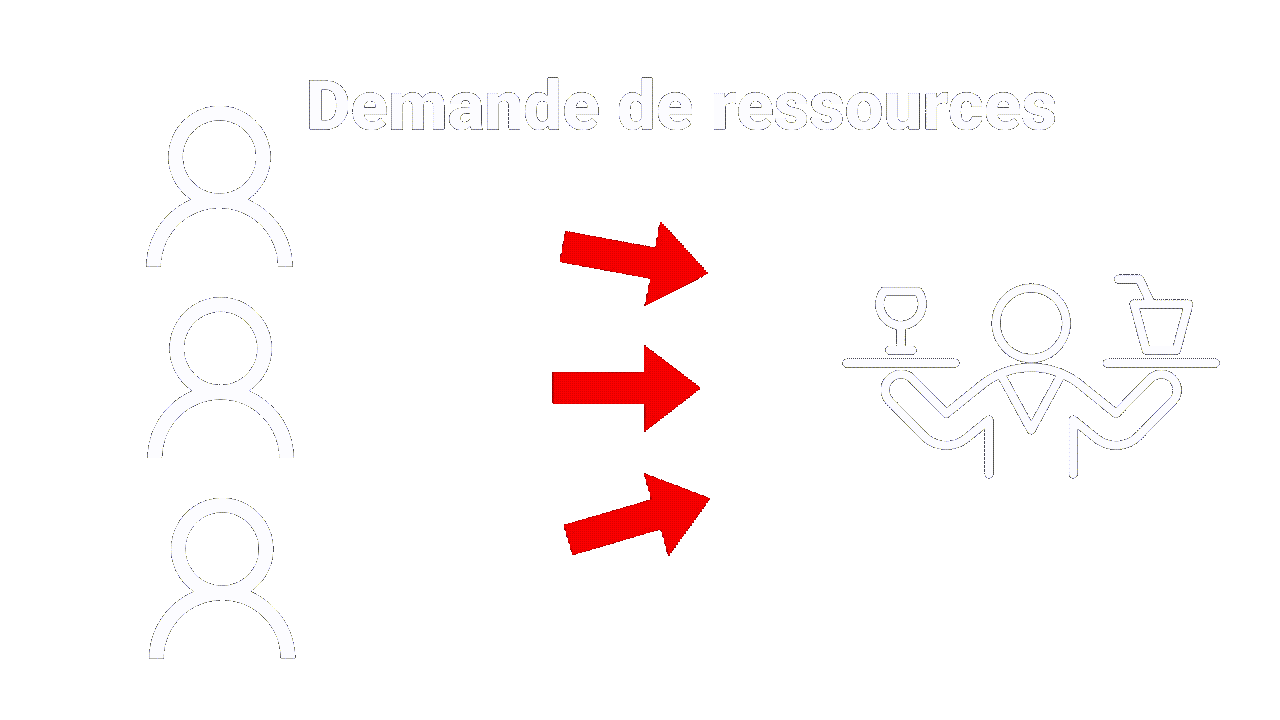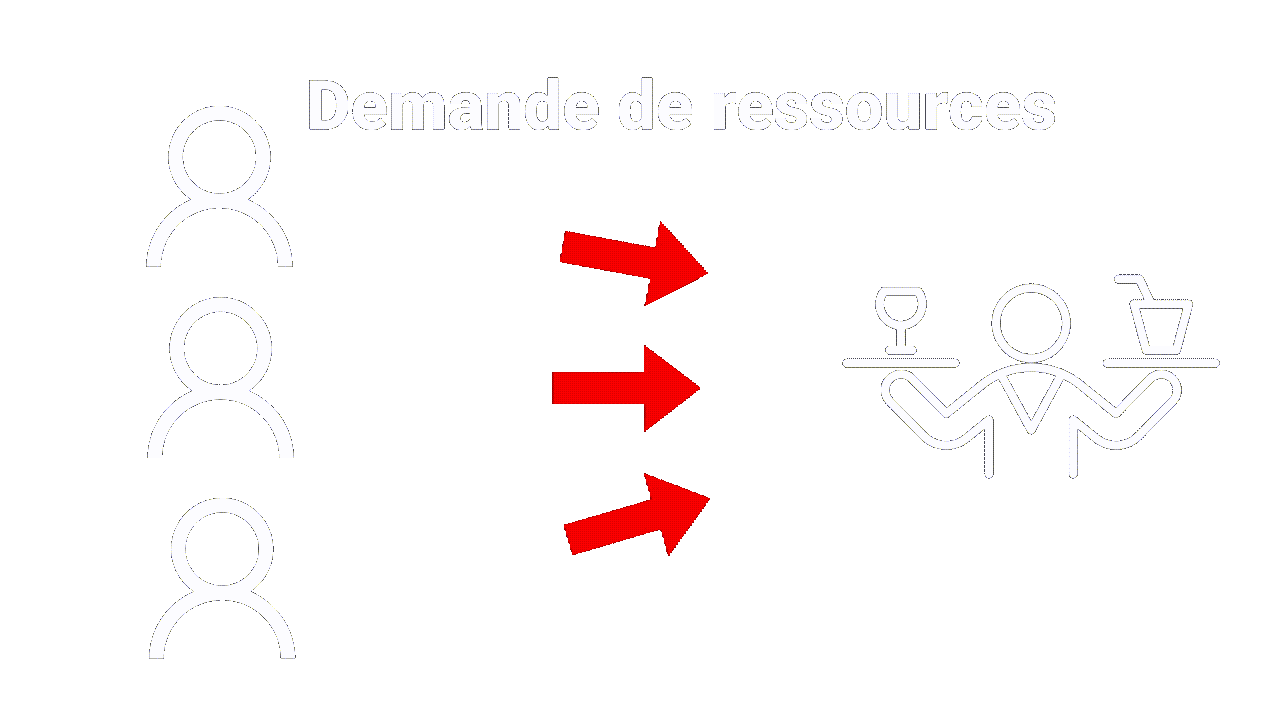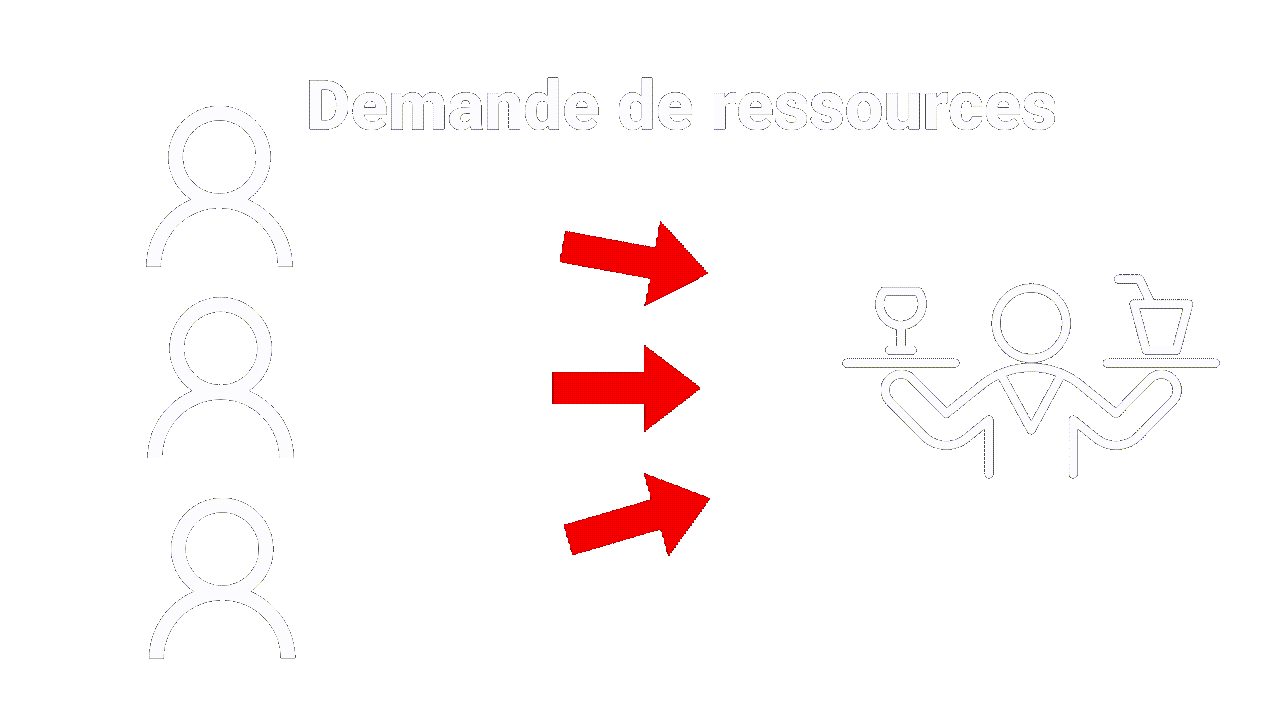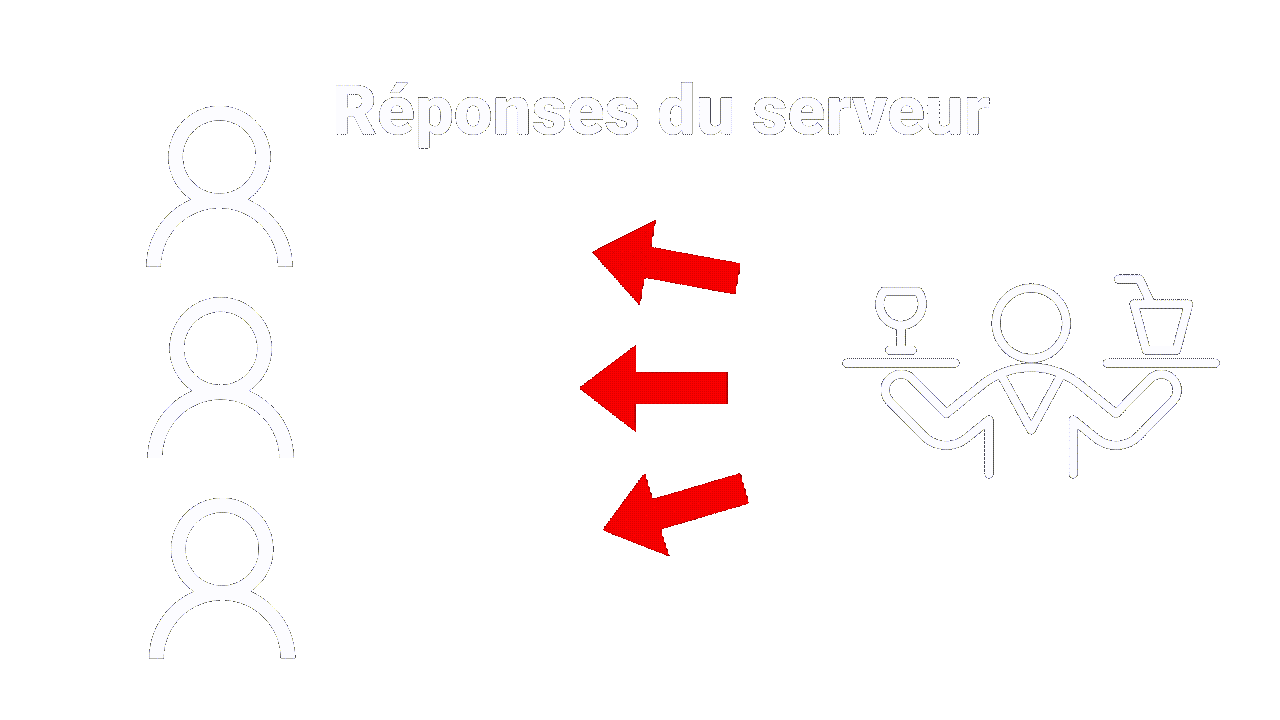 |
|---|
| Multiples demandes |
State-what ? Stateless ?
État-quoi ? Stateless ?
Vous avez peut-être déjà entendu le terme STATELESS auparavant, mais vous ne comprenez pas nécessairement ce que cela signifie pour HTTP.
Prenons l'exemple d'une application de réservation de vols. Lorsqu'un utilisateur effectue une recherche de vols disponibles, le serveur renvoie une liste de résultats correspondant aux critères de recherche de l'utilisateur. Si l'utilisateur effectue une nouvelle recherche pour un vol différent, le serveur ne se souvient pas des résultats de la recherche précédente.
 |
|---|
| Exemple de nature Stateless |
En résumé, la nature "stateless" d'HTTP signifie que chaque demande est indépendante et ne conserve pas d'informations sur les demandes précédentes, ce qui permet une plus grande évolutivité et une optimisation des ressources du serveur.
Néanmoins, de nombreuses applications web fournissent un état, grâce aux cookies et à la gestion de session, tels que les paniers d'achats et les boutiques en ligne.
URL, URI, quelle est la différence ?
Un autre point que je voulais aborder était la différence entre les URL et les URI. Avant cet article, j'avais tendance à me confondre, alors je me suis dit que si c'est utile pour moi, cela pourrait aussi vous être utile !
Les URL et les URI sont des identificateurs utilisés pour localiser des ressources sur le Web.
- Une URL (Uniform Resource Locator) est une adresse Web qui identifie l'emplacement d'une ressource spécifique sur Internet, telle qu'une page Web, une image ou un fichier téléchargeable. Elle inclut le nom de domaine, le protocole utilisé pour accéder à la ressource (HTTP, HTTPS, FTP, etc.), le chemin du fichier et parfois des paramètres de requête.
 |
|---|
| Exemple d'URL |
- Une URI (Uniform Resource Identifier) est un identifiant générique pour une ressource Internet. Elle peut être utilisée pour identifier une ressource de plusieurs façons, y compris en utilisant une URL.
La différence avec une URL est qu'une URI peut également identifier une ressource à l'aide d'un nom ou d'une adresse unique, même si la ressource n'est pas accessible en ligne.
Par exemple, le nom d'un livre peut être utilisé comme URI pour identifier ce livre, même s'il n'est pas en ligne.
 |
|---|
| Exemple d'URI |
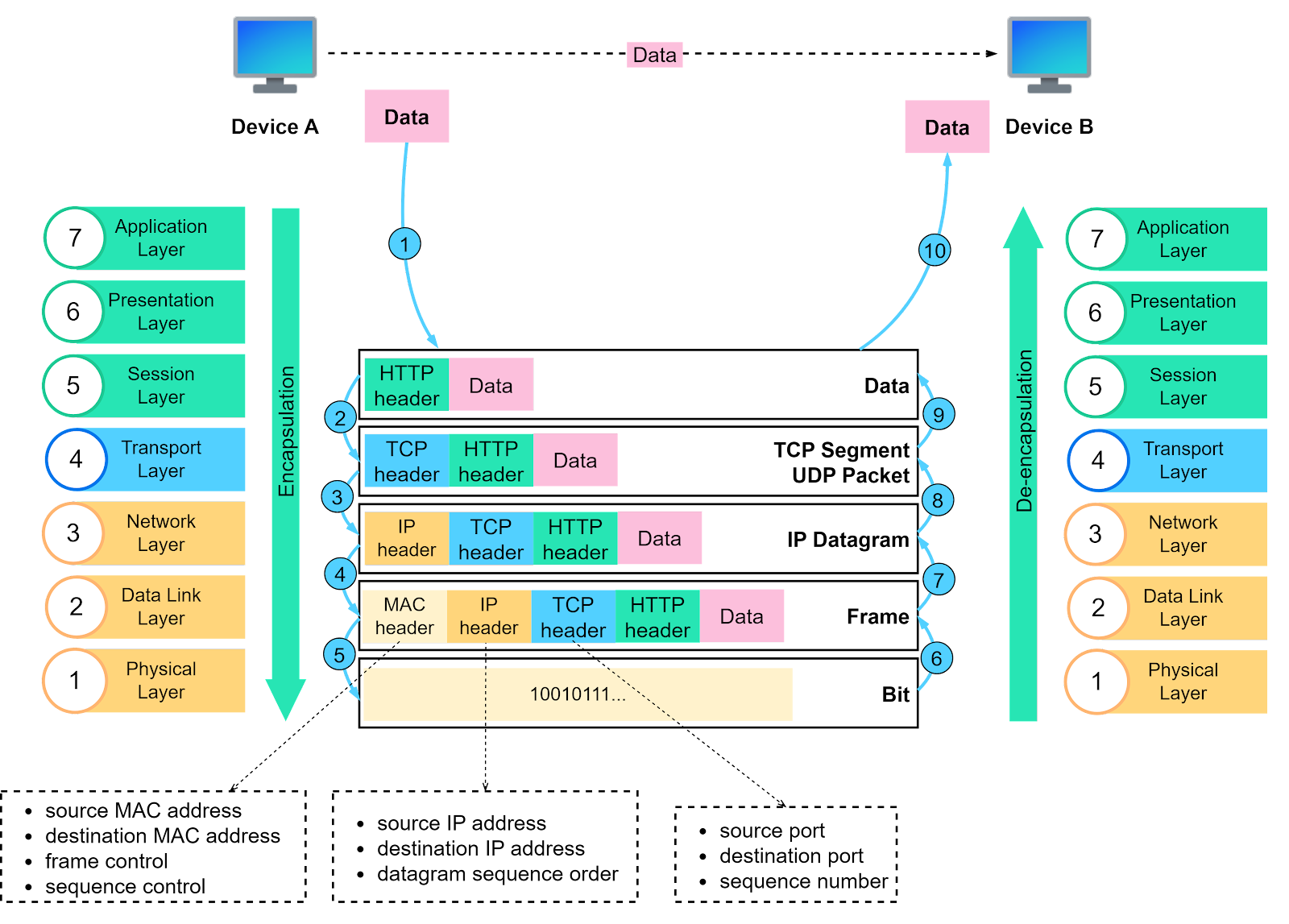
Cher modèle OSI
OSI signifie Open System Interconnection (Interconnexion de Systèmes Ouverts) et est le modèle de référence pour la communication d'ordinateur à ordinateur.
Je ne vais pas revenir sur les 7 couches du modèle OSI, mais vous devriez savoir que HTTP se trouve sur la couche la plus élevée du modèle OSI, la couche d'application.
 |
|---|
| Modèle OSI |
99,9% du temps, HTTP utilise TCP/IP comme protocole de transport (contrairement à UDP).
Nous n'entrerons pas dans les détails du protocole TCP dans cet article, mais simplement, TCP définit comment les données sont formatées, puis envoyées de A à B.
Cependant, comme HTTP se trouve sur une couche supérieure à la couche de transport, il ne se soucie pas de tout ça. Pour HTTP, la seule chose qui compte est :
Je veux une ressource, le serveur m'envoie une réponse
Maintenant que nous avons couvert les bases, voyons ce qui constitue une demande HTTP, en commençant par le premier terme, les VERBES HTTP.
Verbes HTTP
Les verbes HTTP, également appelés méthodes HTTP, sont utilisés pour indiquer l'action à effectuer sur une ressource lors d'une requête HTTP.
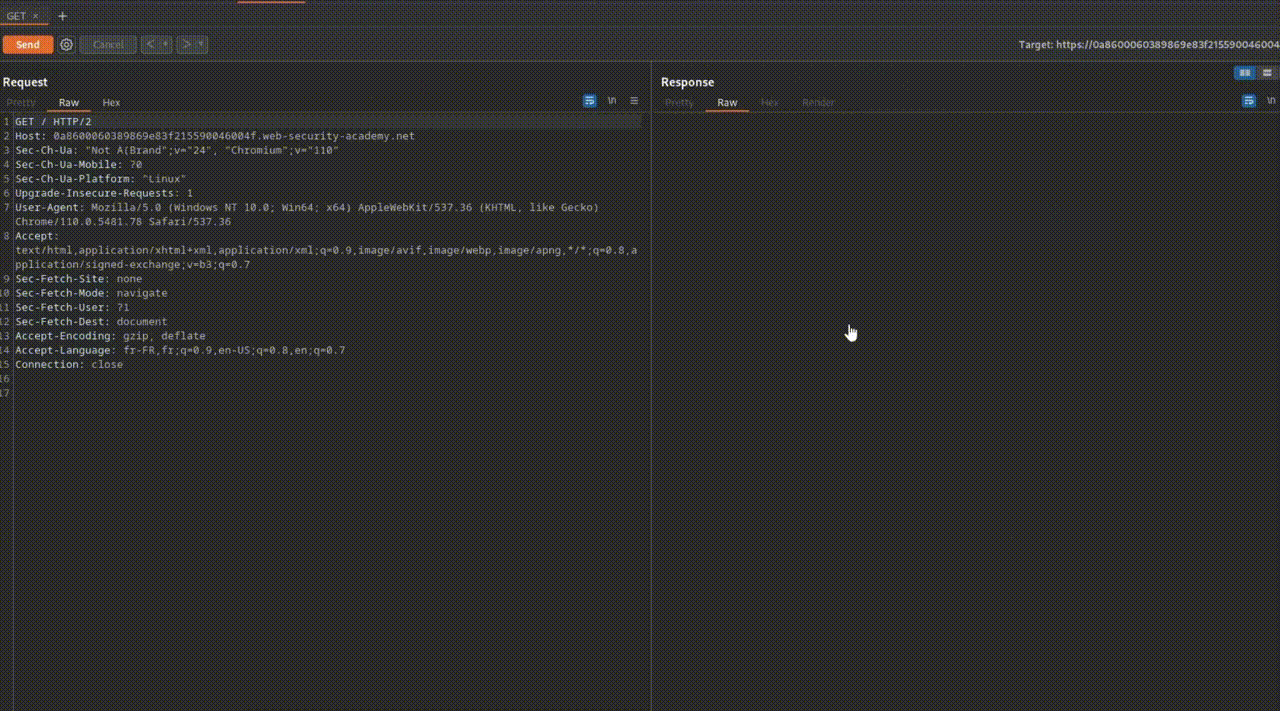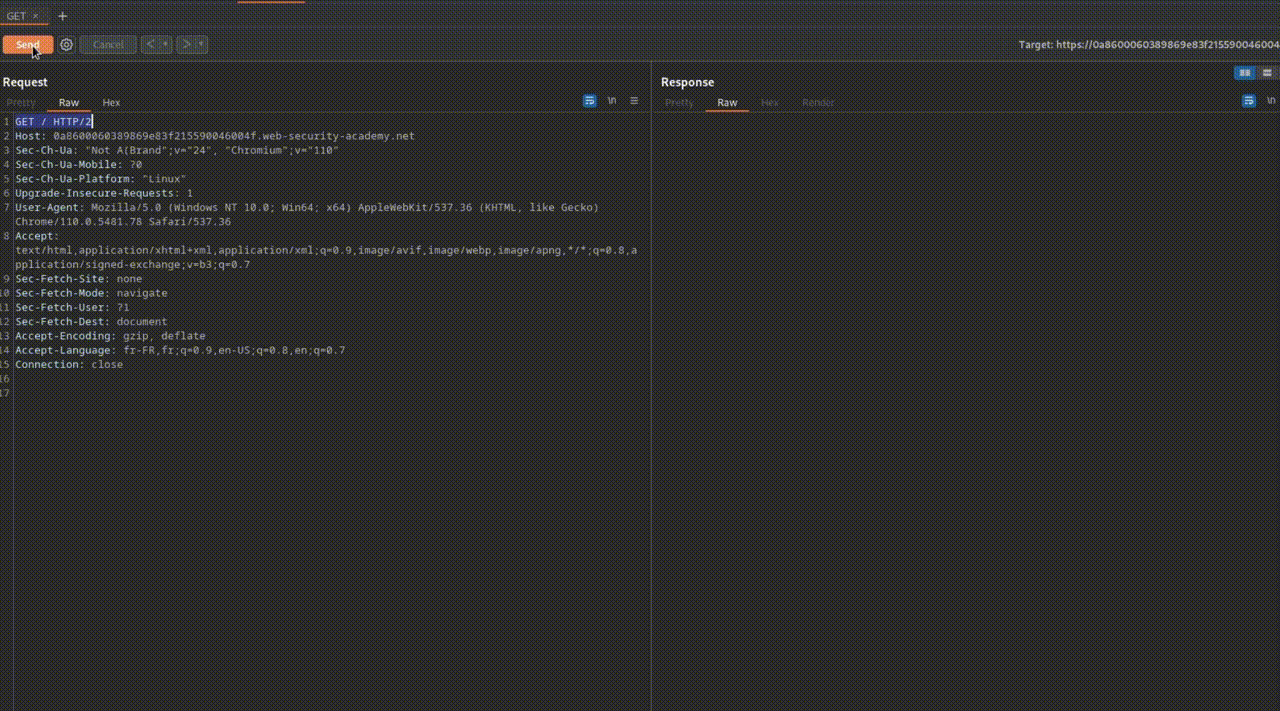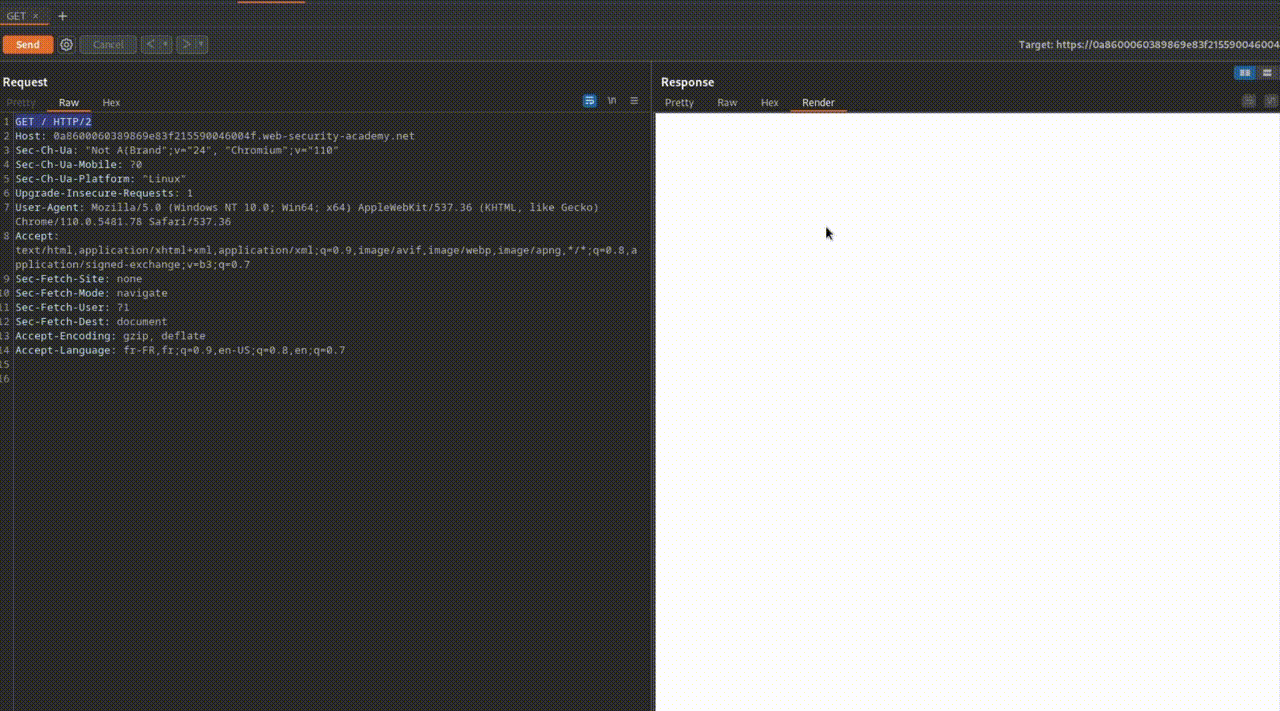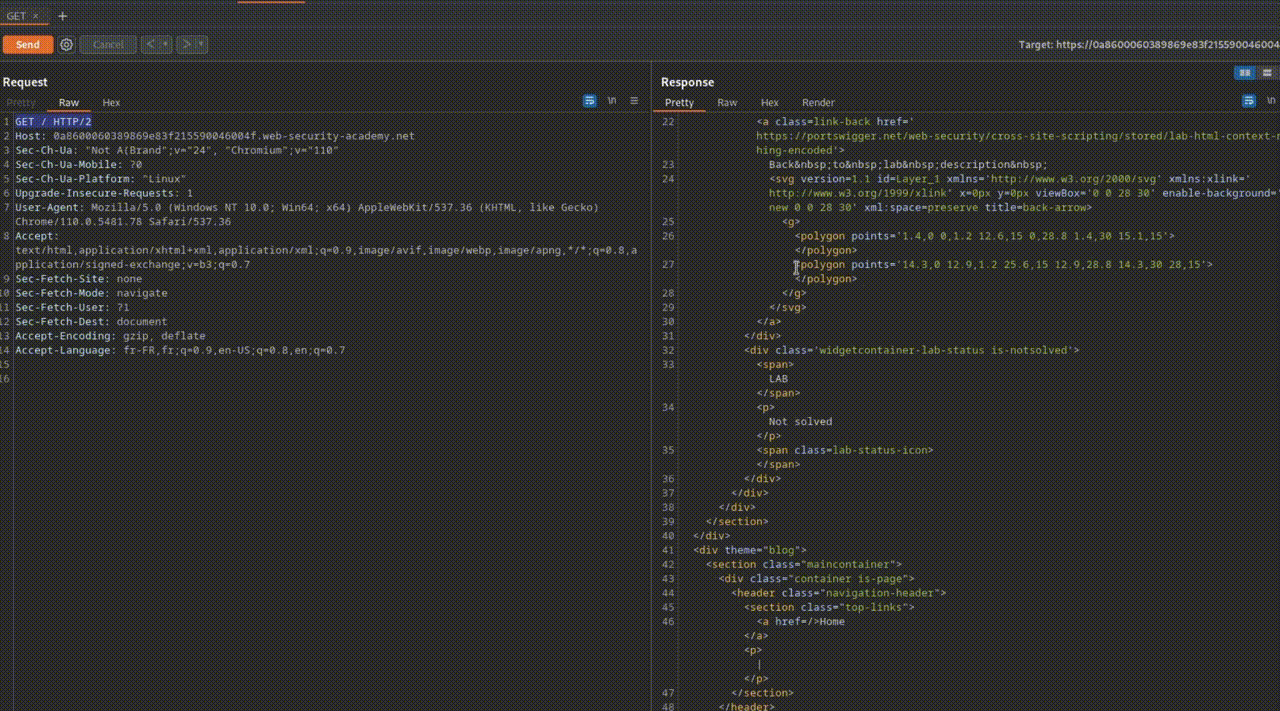
- GET : C'est le verbe le plus courant, utilisé pour récupérer une ressource à partir d'un serveur distant.
- Par exemple, lors de l'accès à une page web comme toto.fr, le navigateur envoie une requête HTTP GET pour récupérer la page hébergée sur le serveur, c'est-à-dire toto.html.
 |
|---|
| Exemple de GET |
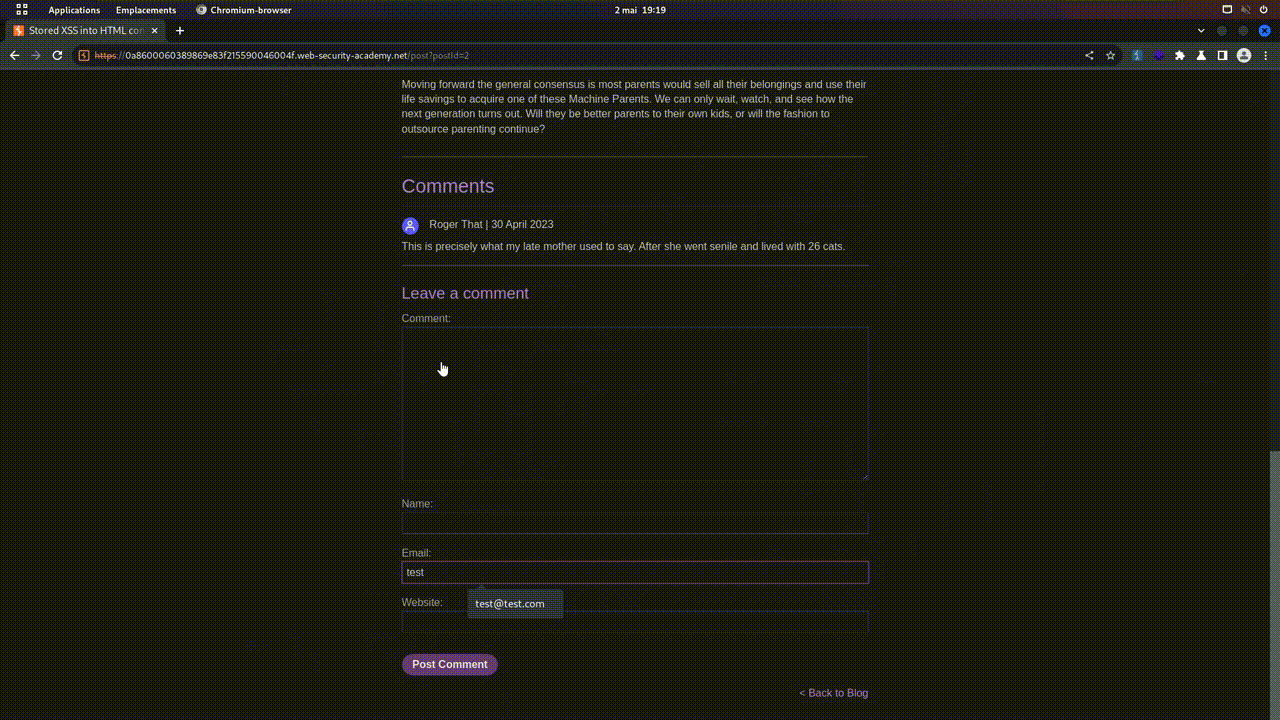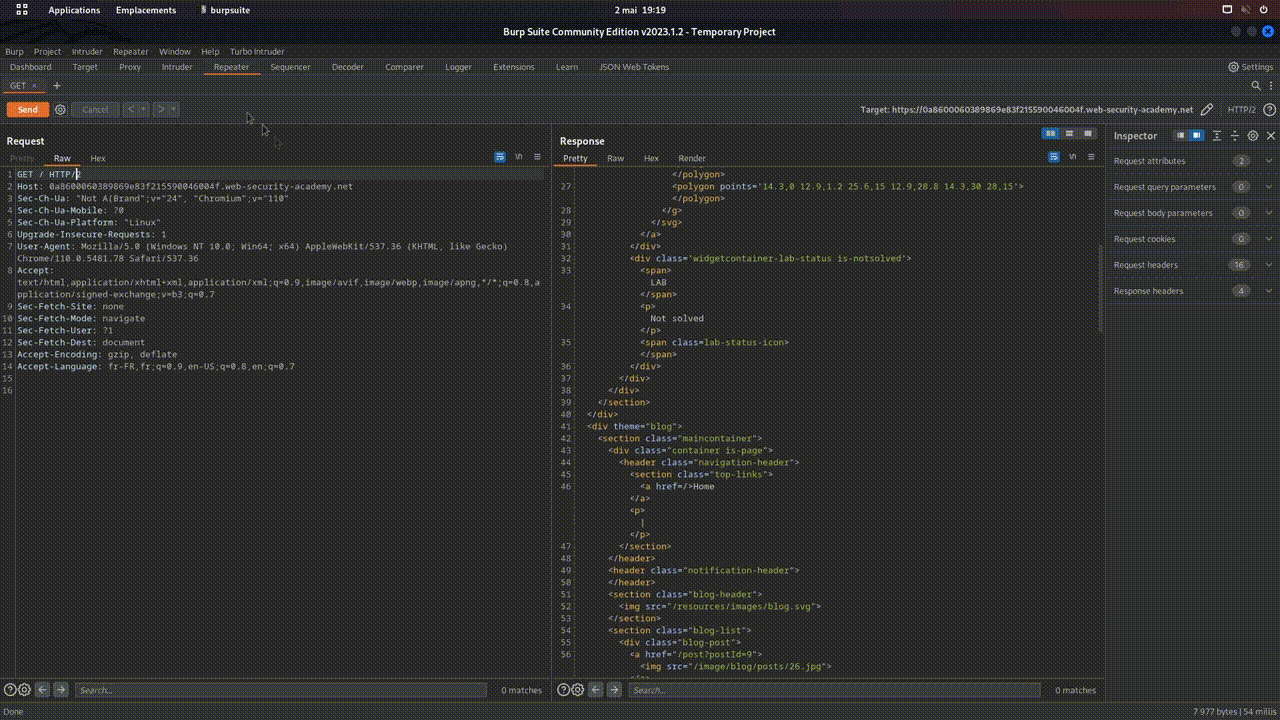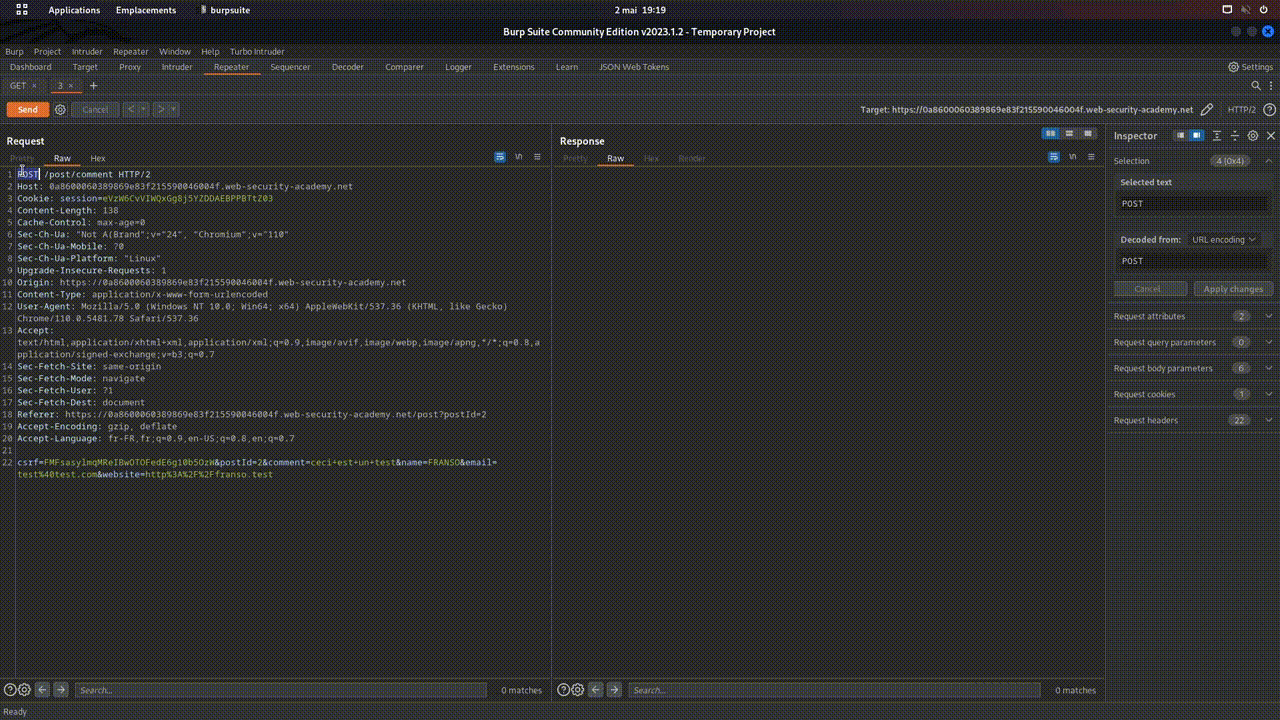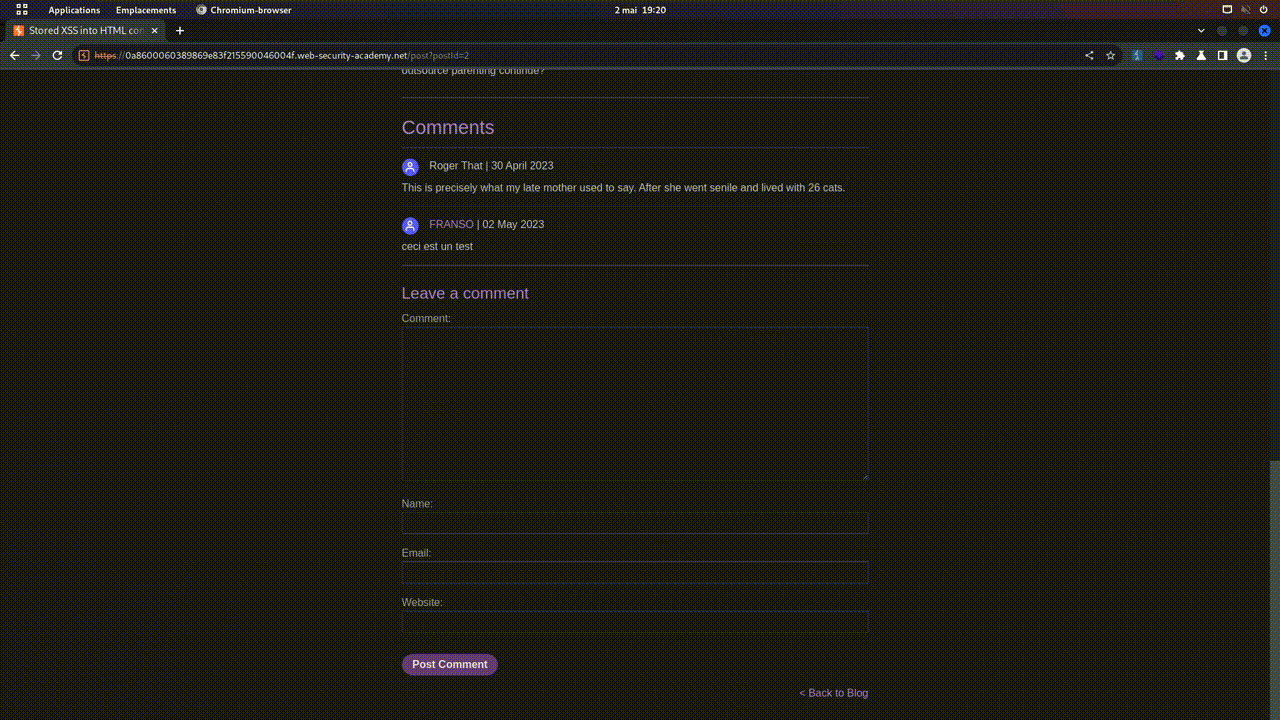
- POST : Ce verbe est utilisé pour envoyer des données au serveur afin de créer une nouvelle ressource.
- Imaginons que sur toto.fr, il y ait un formulaire pour ajouter un article de blog. En cliquant sur "POST", le navigateur enverra une requête POST contenant les données du formulaire, afin que le serveur puisse créer une nouvelle entrée dans la base de données, et donc un nouvel article sur le blog. En tests de sécurité web (pentesting), les requêtes POST, car elles envoient des données au serveur, sont souvent un vecteur d'attaque très utilisé.
 |
|---|
| Exemple de POST |
- PUT : Ce verbe est utilisé pour mettre à jour une ressource existante sur le serveur. Par exemple, sur toto.fr, vous pouvez vous connecter et accéder à votre profil. Si vous souhaitez mettre à jour votre prénom et votre nom de famille, le navigateur enverra une requête PUT contenant les modifications au serveur.
- DELETE : Assez explicite, cette commande supprime une ressource du serveur. Par exemple, si vous supprimez votre compte sur toto.fr, le navigateur enverra une requête HTTP avec DELETE.
Ce sont les principaux verbes HTTP, d'autres existent, mais nous allons les survoler rapidement :
- HEAD : similaire à GET, mais le serveur renvoie uniquement les en-têtes de la réponse, sans le corps. Ce verbe est souvent utilisé pour vérifier si une ressource a été modifiée depuis la dernière requête.
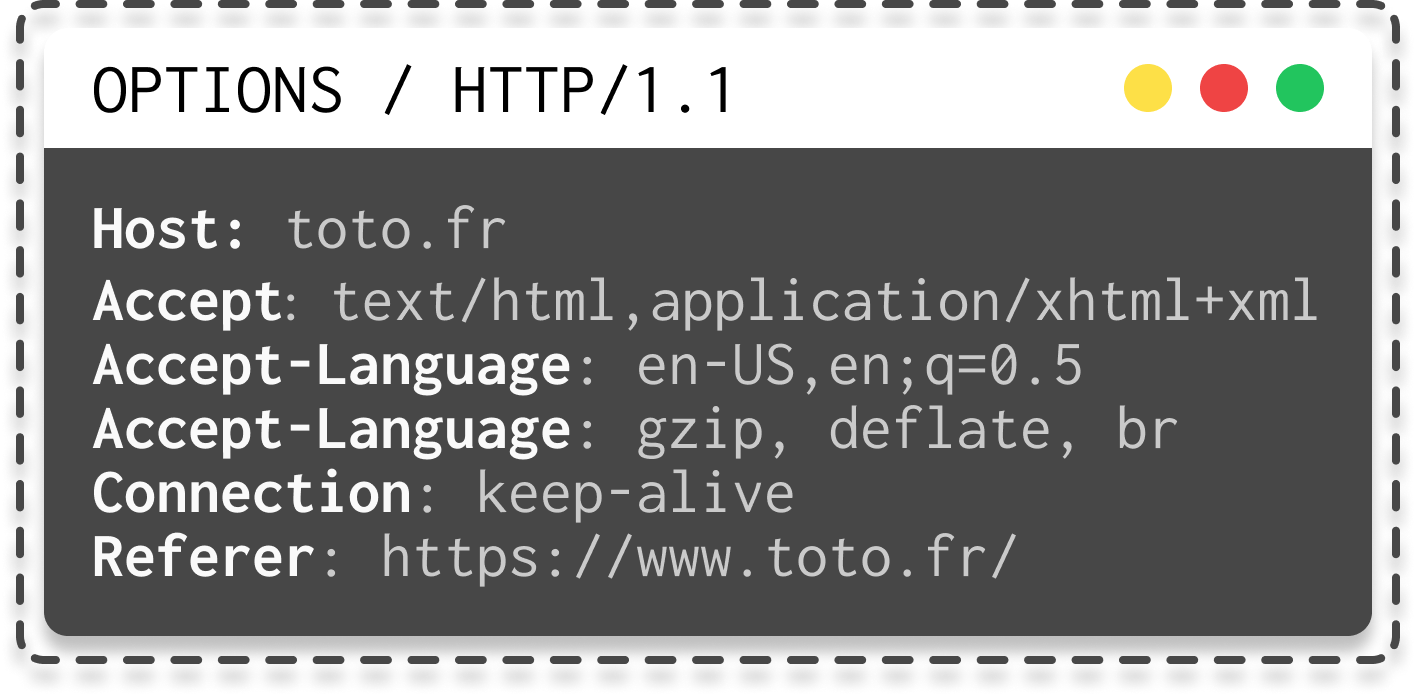
- OPTIONS : utilisé pour obtenir les options de communication disponibles pour une ressource, telles que les verbes HTTP pris en charge par le serveur.
 |
|---|
| Exemple d'options |
- PATCH : utilisé pour effectuer une mise à jour partielle d'une ressource. Au lieu de remplacer l'ensemble de la ressource, le serveur met à jour uniquement les parties spécifiées dans la requête.
- CONNECT : utilisé pour établir une connexion réseau tunnelisée vers le serveur, généralement pour les connexions SSL (Secure Sockets Layer).
 |
|---|
| Exemple de CONNECT |
- TRACE : utilisé pour récupérer une boucle de rappel de demande, permettant de suivre ou de déboguer une demande, peut entraîner des vulnérabilités telles que le Cross Site Tracing.
Ressource demandée
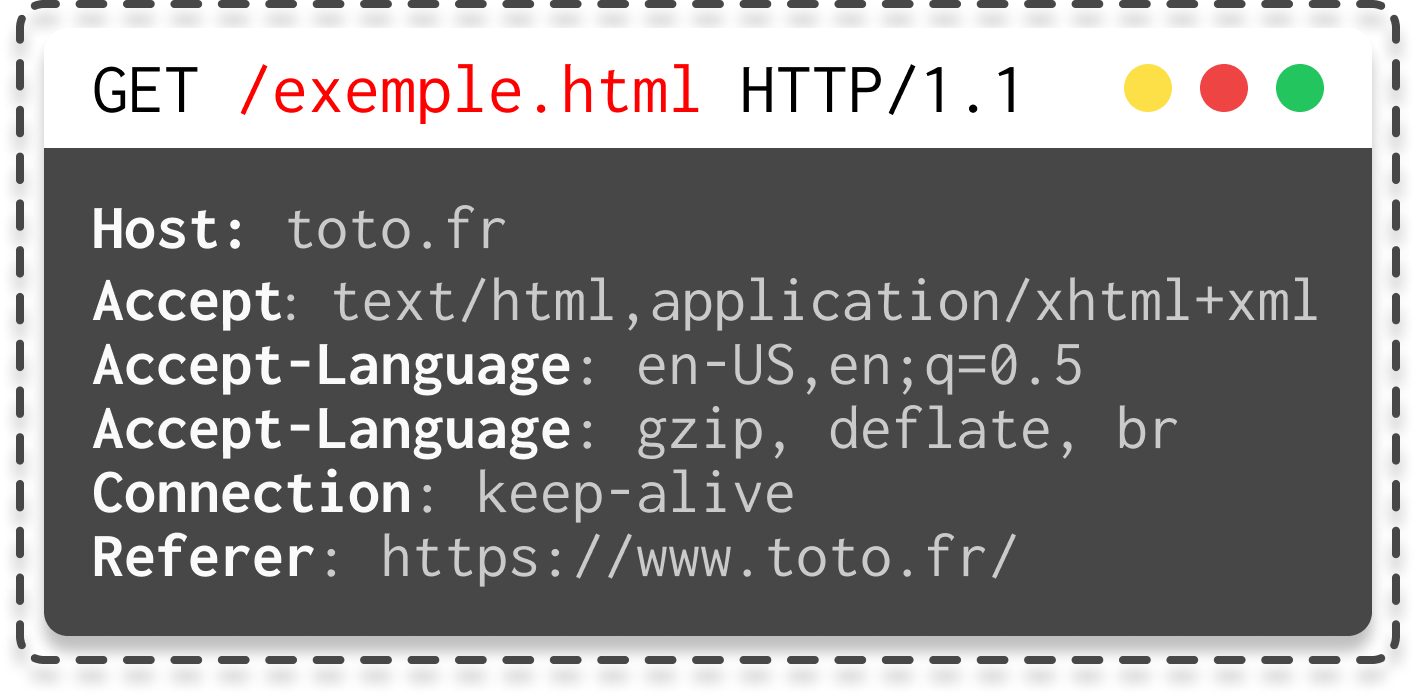
Une fois que vous avez défini le verbe, vous devez indiquer au serveur quelle ressource vous souhaitez, comme vous pouvez le voir.
 |
|---|
| Chemin en rouge |
Version HTTP
Une fois que vous avez choisi la ressource que vous souhaitez, vous devez indiquer au serveur quelle version d'HTTP vous souhaitez utiliser.
Aujourd'hui, la version HTTP 1.1 est la plus courante sur le Web, avec la version HTTP 2 en hausse.
L'histoire des versions HTTP pourrait être le sujet d'un article de blog complet, mais souvenez-vous simplement que dans :
- Version 0/9, chaque demande ouvrait une connexion TCP/IP, ce qui n'était pas très optimisé, et seul le verbe si la ressource était présente.
- Version 1/0 a introduit les en-têtes, que nous verrons plus tard.
- Version 1/1 a introduit le pipelining, un principe simple permettant d'envoyer plusieurs demandes AVANT de recevoir les réponses.
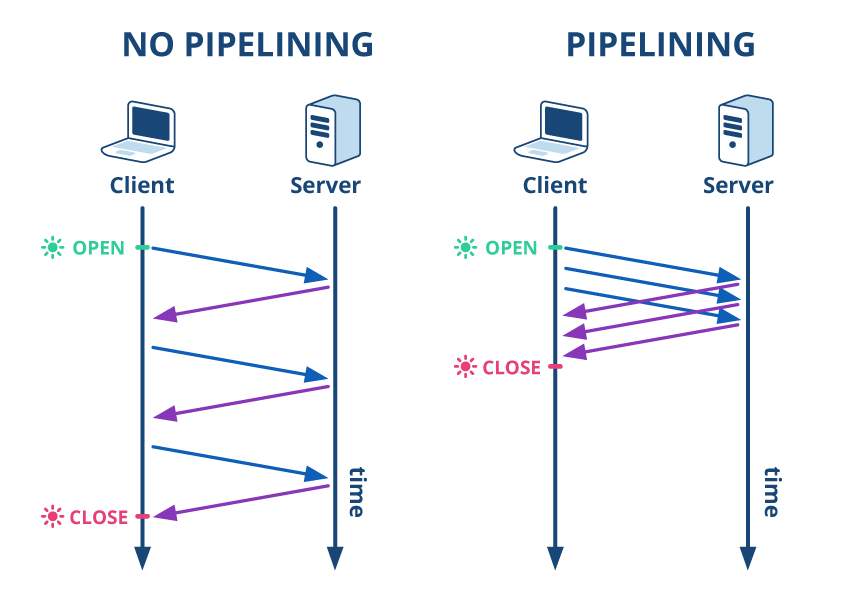 |
|---|
| Pipelining HTTP |
- Version 2 a introduit un encodage binaire plutôt que textuel, ainsi que le multiplexage de protocole pour gérer plusieurs demandes au sein d'une seule connexion TCP/IP (l'en-tête keep-alive a rendu cela possible en 1/1, mais c'est tout).
En-têtes (headers) HTTP
Les en-têtes HTTP sont des informations supplémentaires envoyées avec une requête ou une réponse HTTP. Ces en-têtes contiennent des informations telles que le type de contenu, l'encodage, la langue, le navigateur utilisé et d'autres informations pertinentes pour le traitement de la requête ou de la réponse.
Par exemple :
- Un en-tête Content-Type indique le type de contenu envoyé ou reçu, comme du texte, une image ou une vidéo.
- Un en-tête User-Agent indique le navigateur ou l'application utilisée pour envoyer la demande.
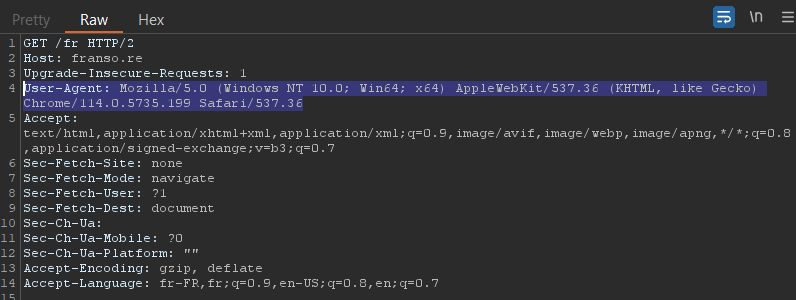 |
|---|
| Exemple d'en-tête User-Agent |
- Un en-tête Accept-Language indique la langue préférée du client pour la réponse.
Les en-têtes HTTP sont importants car ils permettent au serveur et au client de communiquer en détail sur les informations envoyées ou attendues. Cela permet une meilleure gestion des requêtes et des réponses, une meilleure compréhension des besoins du client et une meilleure sécurité en spécifiant certaines restrictions ou autorisations.
Maintenant que nous avons vu tout ce qui constitue une requête, passons à la réponse !
Code de réponse
Une fois que votre demande a été envoyée, plusieurs réponses sont possibles. Ces réponses contiennent un code appelé le code de réponse HTTP.
Il s'agit d'un code à trois chiffres envoyé par un serveur HTTP pour indiquer le résultat d'une demande faite par un client.
Il existe cinq catégories de codes de réponse HTTP : 1xx, 2xx, 3xx, 4xx et 5xx.
- Les codes de réponse HTTP de la série 1xx sont des réponses d'information et indiquent que le serveur a reçu la demande du client et continue de la traiter.
- Par exemple, 101 (Switching Protocols) indique que le serveur a accepté la proposition de changement de protocole envoyée par le client.
- Les codes de réponse HTTP commençant par 2xx indiquent que la demande a été traitée avec succès.
- Par exemple, le code de réponse HTTP 200 signifie que la demande a été traitée avec succès et que la réponse contient les informations demandées.
- Les codes de réponse HTTP commençant par 3xx indiquent une redirection.
- Par exemple, le code de réponse HTTP 301 indique que la ressource demandée a été déplacée de manière permanente vers une nouvelle adresse, et que le client doit mettre à jour son URL.
- Les codes de réponse HTTP commençant par 4xx indiquent une erreur causée par le client.
- Par exemple, le code de réponse HTTP 404 signifie que la ressource demandée n'a pas été trouvée sur le serveur.
- Les codes de réponse HTTP commençant par 5xx indiquent une erreur causée par le serveur.
- Par exemple, le code de réponse HTTP 500 signifie qu'une erreur s'est produite du côté du serveur lors du traitement de la demande.
Ressources
network-protocols-run-the-internet | bytebytego
http-keep-alive-pipelining-multiplexing-and-connection-pooling | haproxy
Hypertext_Transfer_Protocol | wikipedia
HTTP | mozilla